diff --git "a/Python/\347\210\254\350\231\253/python\351\253\230\347\272\247\347\210\254\350\231\253\345\256\236\346\210\230\344\271\213Headers\344\277\241\346\201\257\346\240\241\351\252\214-Cookie.md" "b/Python/\347\210\254\350\231\253/python\351\253\230\347\272\247\347\210\254\350\231\253\345\256\236\346\210\230\344\271\213Headers\344\277\241\346\201\257\346\240\241\351\252\214-Cookie.md"
deleted file mode 100644
index fccea8ba37..0000000000
--- "a/Python/\347\210\254\350\231\253/python\351\253\230\347\272\247\347\210\254\350\231\253\345\256\236\346\210\230\344\271\213Headers\344\277\241\346\201\257\346\240\241\351\252\214-Cookie.md"
+++ /dev/null
@@ -1,68 +0,0 @@
-### python高级爬虫实战之Headers信息校验-Cookie
-
-#### 一、什么是cookie
-
- 上期我们了解了User-Agent,这期我们来看下如何利用Cookie进行用户模拟登录从而进行网站数据的爬取。
-
-首先让我们来了解下什么是Cookie:
-
- Cookie指某些网站为了辨别用户身份、从而储存在用户本地终端上的数据。当客户端在第一次请求网站指定的首页或登录页进行登录之后,服务器端会返回一个Cookie值给客户端。如果客户端为浏览器,将自动将返回的cookie存储下来。当再次访问改网页的其他页面时,自动将cookie值在Headers里传递过去,服务器接受值后进行验证,如合法处理请求,否则拒绝请求。
-
-### 二、如何利用cookie
-
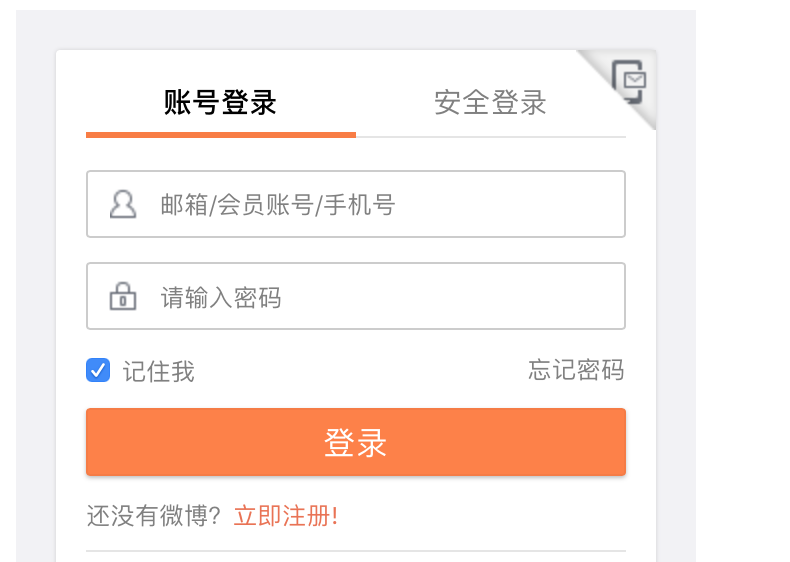
- 举个例子我们要去微博爬取相关数据,首先我们会遇到登录的问题,当然我们可以利用python其他的功能模块进行模拟登录,这里可能会涉及到验证码等一些反爬手段。
-
-
-
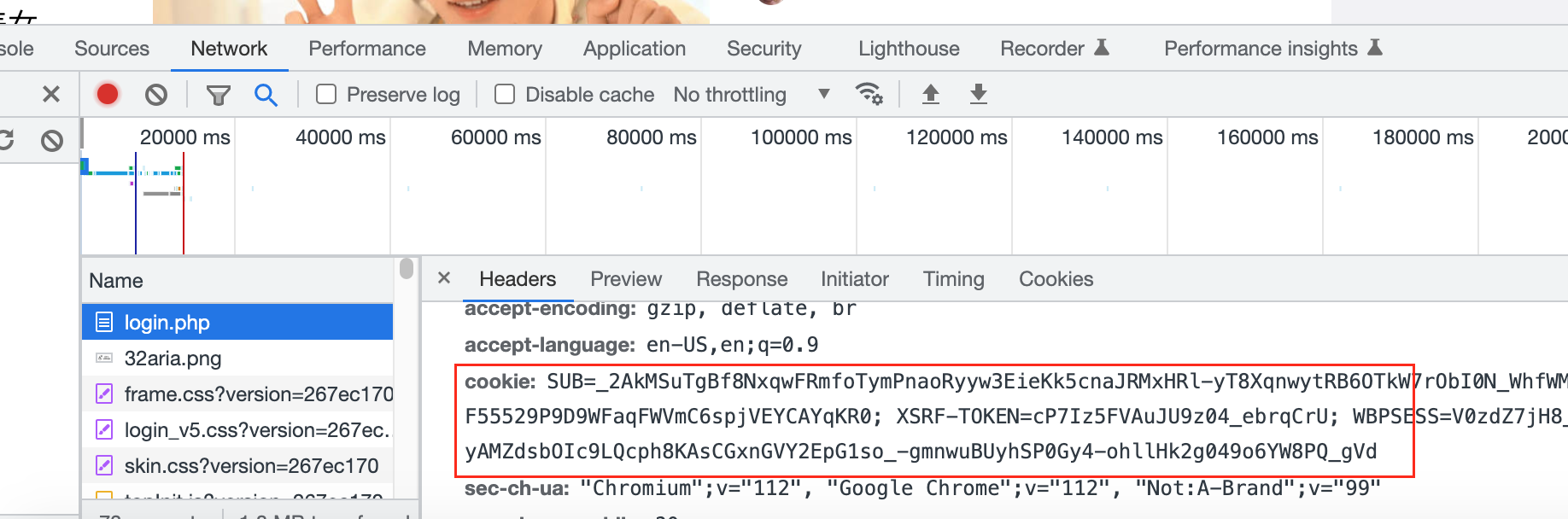
-换个思路,我们登录好了,通过开发者工具“右击” 检查(或者按F12) 获取到对应的cookie,那我们就可以绕个登录的页面,利用cookie继续用户模拟操作从而直接进行操作了。
-
-
-
-利用cookie实现模拟登录的两种方法:
-
-- [ ] 将cookie插入Headers请求头
-
- ```
- Headers={"cookie":"复制的cookie值"}
- ```
-
-
-
-- [ ] 将cookie直接作为requests方法的参数
-
-```
-cookie={"cookie":"复制的cookie值"}
-requests.get(url,cookie=cookie)
-```
-
-#### 三、利用selenium获取cookie,实现用户模拟登录
-
-实现方法:利用selenium模拟浏览器操作,输入用户名,密码 或扫码进行登录,获取到登录的cookie保存成文件,加载文件解析cookie实现用户模拟登录。
-
-```python
-from selenium import webdriver
-from time import sleep
-import json
-#selenium模拟浏览器获取cookie
-def getCookie:
- driver = webdriver.Chrome()
- driver.maximize_window()
- driver.get('https://weibo.co m/login.php')
- sleep(20) # 留时间进行扫码
- Cookies = driver.get_cookies() # 获取list的cookies
- jsCookies = json.dumps(Cookies) # 转换成字符串保存
- with open('cookies.txt', 'w') as f:
- f.write(jsCookies)
-
-def login:
- filename = 'cookies.txt'
- #创建MozillaCookieJar实例对象
- cookie = cookiejar.MozillaCookieJar()
- #从文件中读取cookie内容到变量
- cookie.load(filename, ignore_discard=True, ignore_expires=True)
- response = requests.get('https://weibo.co m/login.php',cookie=cookie)
-```
-
-#### 四、拓展思考
-
- 如果频繁使用一个账号进行登录爬取网站数据有可能导致服务器检查到异常,对当前账号进行封禁,这边我们就需要考虑cookie池的引入了。
\ No newline at end of file
diff --git "a/Python/\347\210\254\350\231\253/python\351\253\230\347\272\247\347\210\254\350\231\253\345\256\236\346\210\230\344\271\213Headers\344\277\241\346\201\257\346\240\241\351\252\214-User-Agent.md" "b/Python/\347\210\254\350\231\253/python\351\253\230\347\272\247\347\210\254\350\231\253\345\256\236\346\210\230\344\271\213Headers\344\277\241\346\201\257\346\240\241\351\252\214-User-Agent.md"
deleted file mode 100644
index 0fa29af29d..0000000000
--- "a/Python/\347\210\254\350\231\253/python\351\253\230\347\272\247\347\210\254\350\231\253\345\256\236\346\210\230\344\271\213Headers\344\277\241\346\201\257\346\240\241\351\252\214-User-Agent.md"
+++ /dev/null
@@ -1,61 +0,0 @@
-### python高级爬虫实战之Headers信息校验-User-Agent
-
- User-agent 是当前网站反爬策略中最基础的一种反爬技术,服务器通过接收请求头中的user-agen的值来判断是否为正常用户访问还是爬虫程序。
-
- 下面举一个简单的例子 爬取我们熟悉的豆瓣网:
-
-```python
-import requests
-url='https://movie.douban.com/'
-resp=requests.get(url)
-print(resp.status_code)
-```
-
-运行结果得到status_code:418
-
-说明我们爬虫程序已经被服务器所拦截,无法正常获取相关网页数据。
-
-我们可以通过返回的状态码来了解服务器的相应情况
-
-- 100–199:信息反馈
-- 200–299:成功反馈
-- 300–399:重定向消息
-- 400–499:客户端错误响应
-- 500–599:服务器错误响应
-
-现在我们利用google chrome浏览器来打开豆瓣网,查看下网页。
-
-正常打开网页后,我们在页面任意地方右击“检查” 打开开发者工具。
-
- -
-
-
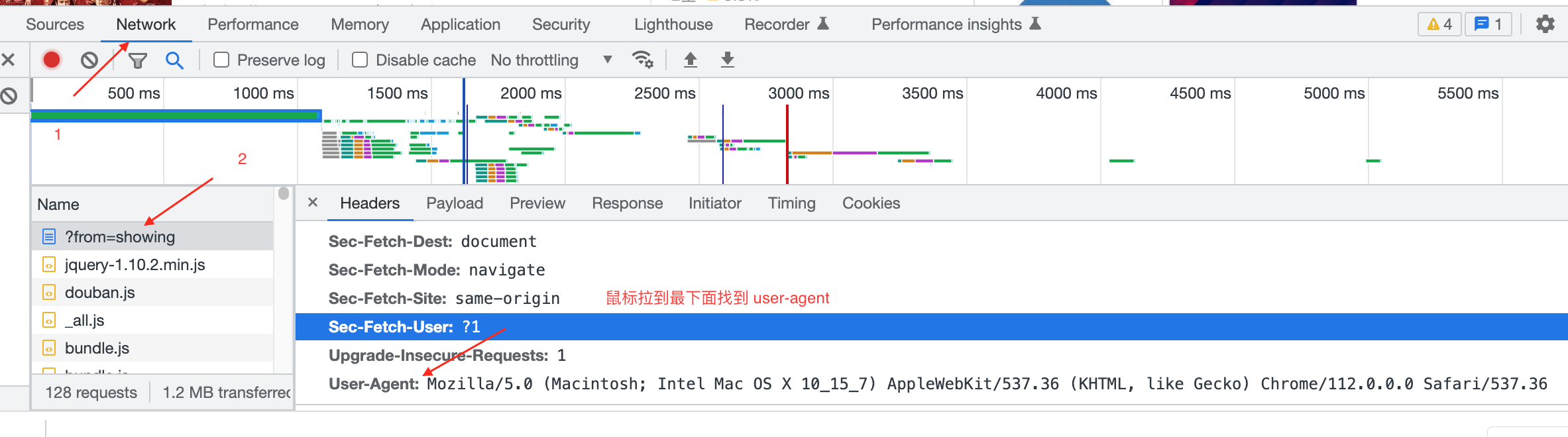
-选择:Network-在Name中随便找一个文件点击后,右边Headers显示内容,鼠标拉到最下面。
-
-
-
-User-Agent:
-
-Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36
-
-我们把这段带到程序中再试下看效果如何。
-
-```python
-import requests
-url='https://movie.douban.com/'
-headers={
-"user-agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
-}
-resp=requests.get(url,headers=headers)
-print(resp.status_code)
-```
-
-完美,执行后返回状态码200 ,说明已经成功骗过服务器拿到了想要的数据。
-
- 对于User-agent 我们可以把它当做一个身份证,这个身份证中会包含很多信息,通过这些信息可以识别出访问者。所以当服务器开启了user-agent认证时,就需要像服务器传递相关的信息进行核对。核对成功,服务器才会返回给用户正确的内容,否则就会拒绝服务。
-
-当然,对于Headers的相关信息还有很多,后续我们再一一讲解,下期见。
-
-
-
diff --git "a/Python/\347\210\254\350\231\253/\345\210\251\347\224\250python\345\256\236\347\216\260\345\260\217\350\257\264\350\207\252\347\224\261.md" "b/Python/\347\210\254\350\231\253/\345\210\251\347\224\250python\345\256\236\347\216\260\345\260\217\350\257\264\350\207\252\347\224\261.md"
deleted file mode 100644
index deb2f6262f..0000000000
--- "a/Python/\347\210\254\350\231\253/\345\210\251\347\224\250python\345\256\236\347\216\260\345\260\217\350\257\264\350\207\252\347\224\261.md"
+++ /dev/null
@@ -1,91 +0,0 @@
-### 利用python实现小说自由
-
-#### 一、用到的相关模块
-
-1.reuqests模块
-
-安装reuqest模块,命令行输入:
-
-```
-pip install requests
-```
-
-2.xpath解析
-
- XPath 即为 XML 路径语言,它是一种用来确定 XML (标准通用标记语言子集)文档中某部分位置的语言。XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。起初 XPath 的提出的初衷是将其作为一个通用的、介于 XPointer 与 XSL 间的语法模型。但是 XPath 很快的被开发者采用来当作小型查询语言。
-
- 简单的来说:Xpath(XML Path Language)是一门在 XML 和 HTML 文档中查找信息的语言,可用来在 XML 和 HTML 文档中对元素和属性进行遍历。
-
- xml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
-
-安装xml:
-
-```
-pip install lxml
-```
-
-
-
-#### 二、实现步骤
-
-1.首先我们打开一个小说的网址:https://www.qu-la.com/booktxt/17437775116/
-
-2.右击“检查” 查看下这个网页的相关代码情况
-
-
-
-
-
-选择:Network-在Name中随便找一个文件点击后,右边Headers显示内容,鼠标拉到最下面。
-
-
-
-User-Agent:
-
-Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36
-
-我们把这段带到程序中再试下看效果如何。
-
-```python
-import requests
-url='https://movie.douban.com/'
-headers={
-"user-agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"
-}
-resp=requests.get(url,headers=headers)
-print(resp.status_code)
-```
-
-完美,执行后返回状态码200 ,说明已经成功骗过服务器拿到了想要的数据。
-
- 对于User-agent 我们可以把它当做一个身份证,这个身份证中会包含很多信息,通过这些信息可以识别出访问者。所以当服务器开启了user-agent认证时,就需要像服务器传递相关的信息进行核对。核对成功,服务器才会返回给用户正确的内容,否则就会拒绝服务。
-
-当然,对于Headers的相关信息还有很多,后续我们再一一讲解,下期见。
-
-
-
diff --git "a/Python/\347\210\254\350\231\253/\345\210\251\347\224\250python\345\256\236\347\216\260\345\260\217\350\257\264\350\207\252\347\224\261.md" "b/Python/\347\210\254\350\231\253/\345\210\251\347\224\250python\345\256\236\347\216\260\345\260\217\350\257\264\350\207\252\347\224\261.md"
deleted file mode 100644
index deb2f6262f..0000000000
--- "a/Python/\347\210\254\350\231\253/\345\210\251\347\224\250python\345\256\236\347\216\260\345\260\217\350\257\264\350\207\252\347\224\261.md"
+++ /dev/null
@@ -1,91 +0,0 @@
-### 利用python实现小说自由
-
-#### 一、用到的相关模块
-
-1.reuqests模块
-
-安装reuqest模块,命令行输入:
-
-```
-pip install requests
-```
-
-2.xpath解析
-
- XPath 即为 XML 路径语言,它是一种用来确定 XML (标准通用标记语言子集)文档中某部分位置的语言。XPath 基于 XML 的树状结构,提供在数据结构树中找寻节点的能力。起初 XPath 的提出的初衷是将其作为一个通用的、介于 XPointer 与 XSL 间的语法模型。但是 XPath 很快的被开发者采用来当作小型查询语言。
-
- 简单的来说:Xpath(XML Path Language)是一门在 XML 和 HTML 文档中查找信息的语言,可用来在 XML 和 HTML 文档中对元素和属性进行遍历。
-
- xml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
-
-安装xml:
-
-```
-pip install lxml
-```
-
-
-
-#### 二、实现步骤
-
-1.首先我们打开一个小说的网址:https://www.qu-la.com/booktxt/17437775116/
-
-2.右击“检查” 查看下这个网页的相关代码情况
-
-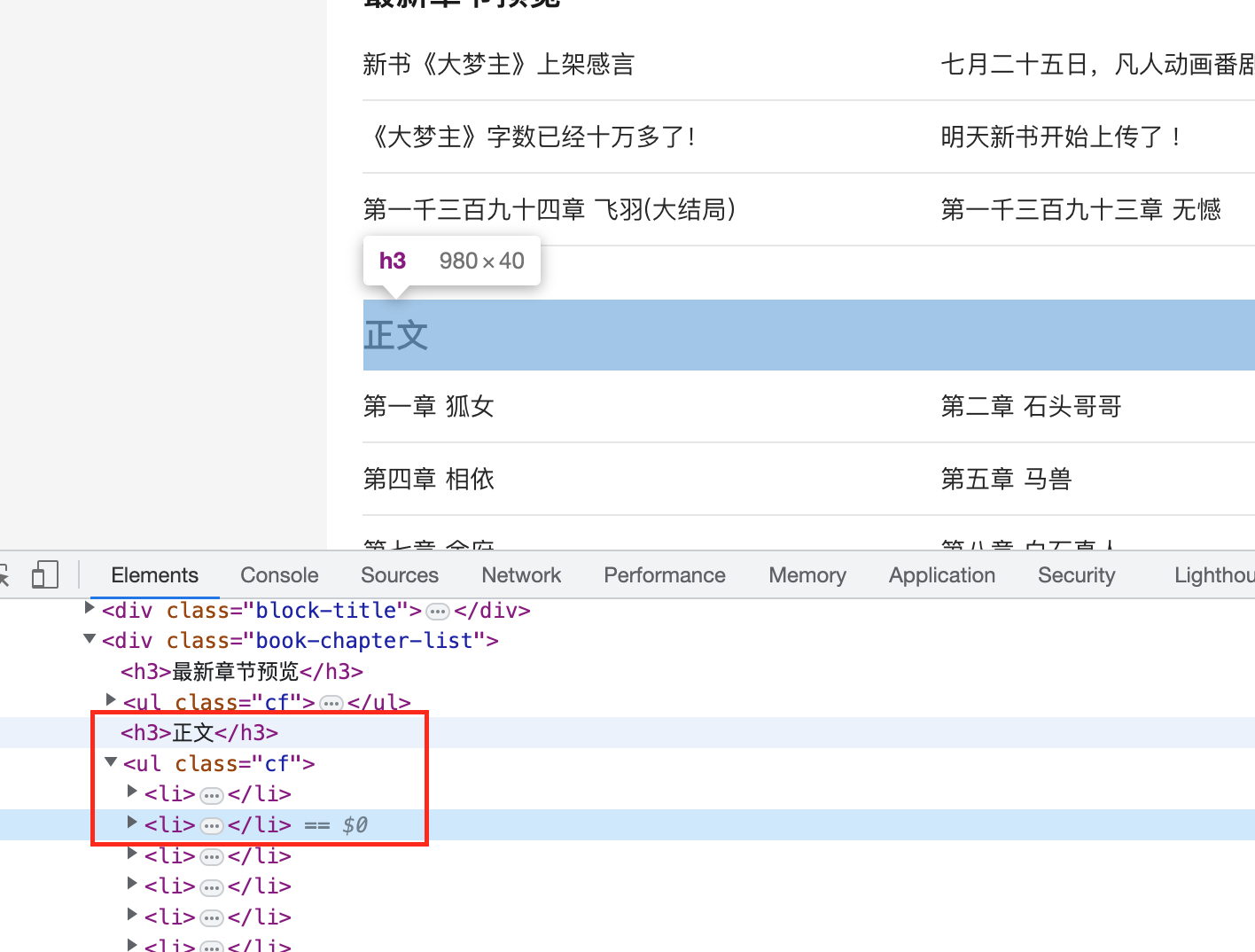 -
-我们可以发现所有的内容都被包裹在
-
-通过xpath 解析出每个章节的标题,和链接。
-
-3.根据对应的链接获取每个章节的文本。同样的方法找到章节文本的具体位置
-
-//*[@id="txt"]
-
-
-
-我们可以发现所有的内容都被包裹在
-
-通过xpath 解析出每个章节的标题,和链接。
-
-3.根据对应的链接获取每个章节的文本。同样的方法找到章节文本的具体位置
-
-//*[@id="txt"]
-
-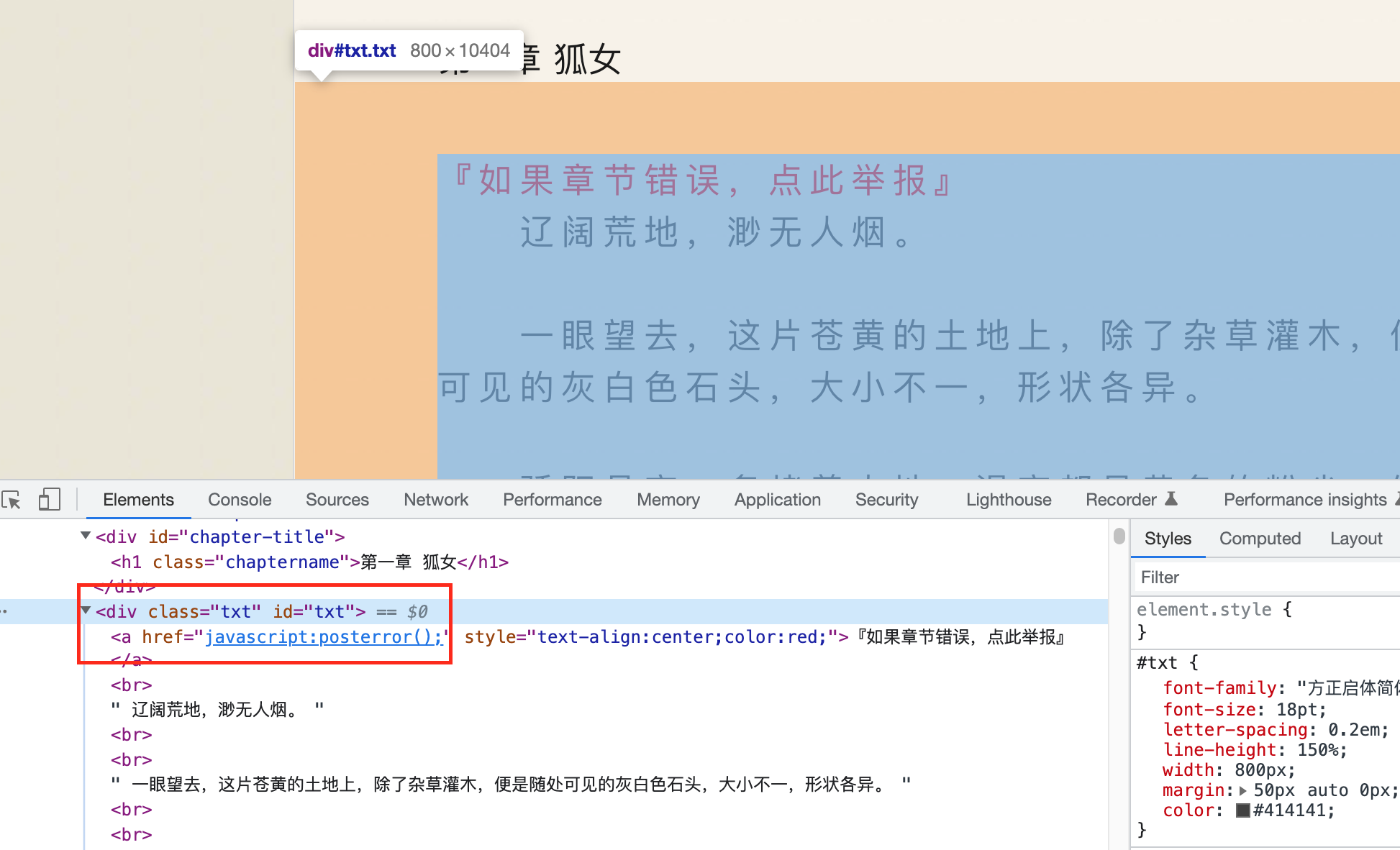 -
-3.for 循环获取所有链接的文本,保存为Txt文件。
-
-#### 三、代码展示
-
-```python
-import requests
-from lxml import etree
-def getNovel():
- headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'};
- html = requests.get('https://www.qu-la.com/booktxt/17437775116/',headers=headers).content
- doc=etree.HTML(html)
- contents=doc.xpath('//*[ @id="list"]/div[3]/ul[2]') #获取到小说的所有章节
- for content in contents:
- links=content.xpath('li/a/@href') #获取每个章节的链接
- for link in links: #循环处理每个章节
- url='https://www.qu-la.com'+link #拼接章节url
- html=requests.get(url).text
- doc=etree.HTML(html)
- content = doc.xpath('//*[@id="txt"]/text()') #获取章节的正文
- title = doc.xpath('//*[@id="chapter-title"]/h1/text()') #获取标题
- #所有的保存到一个文件里面
- with open('books/凡人修仙之仙界篇.txt', 'a') as file:
- file.write(title[0])
- print('正在下载{}'.format(title[0]))
- for items in content:
- file.write(item)
-
- print('下载完成')
-getNovel() #调用函数
-```
-
-#### 四、拓展思考
-
-1.写一个搜索界面,用户输入书名自主下载对应的小说。
-
-2.引入多进程异步下载,提高小说的下载速度。
-
-
-
diff --git a/README.md b/README.md
index 8ad293ad89..8e1fc968d4 100755
--- a/README.md
+++ b/README.md
@@ -16,14 +16,24 @@
更多精彩内容将发布在公众号 **JavaEdge**,公众号提供大量求职面试资料,后台回复 "面试" 即可领取。
本号系统整理了Java高级工程师必备技能点,帮你理清纷杂面试知识点,有的放矢。
+我本人也是基于这些知识体系,在各种求职征途中拿到百度、携程、华为、中兴、顺丰、帆软、货拉拉等offer。
+
+
-
-3.for 循环获取所有链接的文本,保存为Txt文件。
-
-#### 三、代码展示
-
-```python
-import requests
-from lxml import etree
-def getNovel():
- headers = {'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/84.0.4147.125 Safari/537.36'};
- html = requests.get('https://www.qu-la.com/booktxt/17437775116/',headers=headers).content
- doc=etree.HTML(html)
- contents=doc.xpath('//*[ @id="list"]/div[3]/ul[2]') #获取到小说的所有章节
- for content in contents:
- links=content.xpath('li/a/@href') #获取每个章节的链接
- for link in links: #循环处理每个章节
- url='https://www.qu-la.com'+link #拼接章节url
- html=requests.get(url).text
- doc=etree.HTML(html)
- content = doc.xpath('//*[@id="txt"]/text()') #获取章节的正文
- title = doc.xpath('//*[@id="chapter-title"]/h1/text()') #获取标题
- #所有的保存到一个文件里面
- with open('books/凡人修仙之仙界篇.txt', 'a') as file:
- file.write(title[0])
- print('正在下载{}'.format(title[0]))
- for items in content:
- file.write(item)
-
- print('下载完成')
-getNovel() #调用函数
-```
-
-#### 四、拓展思考
-
-1.写一个搜索界面,用户输入书名自主下载对应的小说。
-
-2.引入多进程异步下载,提高小说的下载速度。
-
-
-
diff --git a/README.md b/README.md
index 8ad293ad89..8e1fc968d4 100755
--- a/README.md
+++ b/README.md
@@ -16,14 +16,24 @@
更多精彩内容将发布在公众号 **JavaEdge**,公众号提供大量求职面试资料,后台回复 "面试" 即可领取。
本号系统整理了Java高级工程师必备技能点,帮你理清纷杂面试知识点,有的放矢。
+我本人也是基于这些知识体系,在各种求职征途中拿到百度、携程、华为、中兴、顺丰、帆软、货拉拉等offer。
+
+ ## 3 笔者简介
+
### [阿里云栖社区博客专家](https://yq.aliyun.com/users/article?spm=a2c4e.8091938.headeruserinfo.3.65993d6eqaQ0O6)
+
+
### [腾讯云自媒体邀约计划作者](https://cloud.tencent.com/developer/user/1752328)
+
+
+
+
## 3 笔者简介
+
### [阿里云栖社区博客专家](https://yq.aliyun.com/users/article?spm=a2c4e.8091938.headeruserinfo.3.65993d6eqaQ0O6)
+
+
### [腾讯云自媒体邀约计划作者](https://cloud.tencent.com/developer/user/1752328)
+
+
+
+
-## 4 目录结构
+## 4 目录结构(不断优化中)
| 数据结构与算法 | 操作系统 | 网络 | 面向对象 | 数据存储 | Java | 架构设计 | 框架 | 编程规范 | 职业规划 |
| :--------: | :---------: | :---------: | :---------: | :---------: | :---------:| :---------: | :-------: | :-------:| :------:|
@@ -83,6 +93,15 @@
### :memo: 职业规划
+## QQ 技术交流群
+
+为大家提供一个学习交流平台,在这里你可以自由地讨论技术问题。
+
+ +
+## 微信交流群
+
+
+## 微信交流群
+ +
### 本人微信
+
### 本人微信
 @@ -95,17 +114,4 @@
### 绘图工具
- [draw.io](https://www.draw.io/)
-- keynote
-
-再分享我整理汇总的一些 Java 面试相关资料(亲自验证,严谨科学!别再看网上误导人的垃圾面试题!!!),助你拿到更多 offer!
-
-
-
-[点击获取更多经典必读电子书!](https://mp.weixin.qq.com/s?__biz=MzUzNTY5MzA3MQ==&mid=2247497273&idx=1&sn=b0f1e2e03cd7de3ce5d93cc8793d6d88&chksm=fa832459cdf4ad4fb046c0beb7e87ecea48f338278846679ef65238af45f0a135720e7061002&token=766333302&lang=zh_CN#rd)
-
-2023年最新Java学习路线一条龙:
-
-[](https://www.nowcoder.com/discuss/353159357007339520?sourceSSR=users)
-
-
-再给大家推荐一个学习 前后端软件开发 和准备Java 面试的公众号[【JavaEdge】](https://mp.weixin.qq.com/s?__biz=MzUzNTY5MzA3MQ==&mid=2247498257&idx=1&sn=b09d88691f9bfd715e000b69ef61227e&chksm=fa832871cdf4a1675d4491727399088ca488fa13e0a3cdf2ece3012265e5a3ef273dff540879&token=766333302&lang=zh_CN#rd)(强烈推荐!)
+- keynote
\ No newline at end of file
@@ -95,17 +114,4 @@
### 绘图工具
- [draw.io](https://www.draw.io/)
-- keynote
-
-再分享我整理汇总的一些 Java 面试相关资料(亲自验证,严谨科学!别再看网上误导人的垃圾面试题!!!),助你拿到更多 offer!
-
-
-
-[点击获取更多经典必读电子书!](https://mp.weixin.qq.com/s?__biz=MzUzNTY5MzA3MQ==&mid=2247497273&idx=1&sn=b0f1e2e03cd7de3ce5d93cc8793d6d88&chksm=fa832459cdf4ad4fb046c0beb7e87ecea48f338278846679ef65238af45f0a135720e7061002&token=766333302&lang=zh_CN#rd)
-
-2023年最新Java学习路线一条龙:
-
-[](https://www.nowcoder.com/discuss/353159357007339520?sourceSSR=users)
-
-
-再给大家推荐一个学习 前后端软件开发 和准备Java 面试的公众号[【JavaEdge】](https://mp.weixin.qq.com/s?__biz=MzUzNTY5MzA3MQ==&mid=2247498257&idx=1&sn=b09d88691f9bfd715e000b69ef61227e&chksm=fa832871cdf4a1675d4491727399088ca488fa13e0a3cdf2ece3012265e5a3ef273dff540879&token=766333302&lang=zh_CN#rd)(强烈推荐!)
+- keynote
\ No newline at end of file